Große Sprachmodelle werden zunehmend als automatisierte Prüfer in Code-Generierungs- und Modernisierungspipelines eingesetzt. Eine aktuelle Studie von IBM Research zeigt jedoch, dass dieser Ansatz bei Legacy-Technologien wie COBOL deutliche Schwächen aufweist – und ohne ergänzende Maßnahmen nur eingeschränkt zuverlässig ist.
Die Autoren untersuchten den Einsatz sogenannter „LLMs as a Judge“ (LaaJ) in einem industriellen Szenario zur Modernisierung von Legacy-Systemen. Am Beispiel automatisch erzeugter COBOL-Programme analysierten sie, wie gut produktiv eingesetzte Sprachmodelle domänenspezifische Fehler erkennen. Das Ergebnis falle ernüchternd aus: Ohne zusätzliche Unterstützung identifizierten die Modelle im Schnitt lediglich rund 45 Prozent der tatsächlich vorhandenen Probleme.
Besonders problematisch seien dabei Fehler, die tiefes Domänenwissen erfordern, etwa fehlende Initialisierungen, unzureichende Statusprüfungen oder fehlerhafte Ablaufsteuerungen. Solche Schwächen würden von allgemeinen Sprachmodellen häufig übersehen, da sie eher auf sichtbare Muster reagieren als auf implizite fachliche Anforderungen, so die Autoren.
Um diese systematischen Blindstellen zu adressieren, entwickelten die Forscher einen hybriden Ansatz. Zunächst wurde eine Taxonomie typischer Bewertungsfehler auf Basis von Expertenanalysen erstellt. Darauf aufbauend entstand ein leichtgewichtiges, regelbasiertes Analysewerkzeug, das COBOL-Code auf über 30 bekannte Problemtypen prüft. Die daraus abgeleiteten Hinweise („analytic hints“) wurden anschließend direkt in den Bewertungs-Prompt der Sprachmodelle eingebettet.
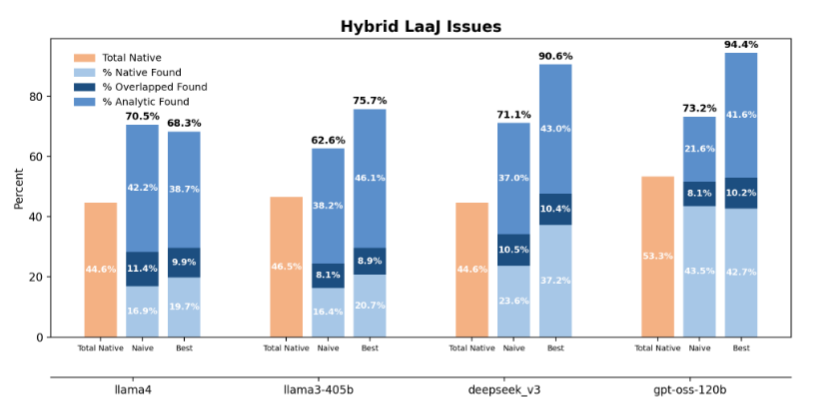
Abbildung: Erkennungsraten hybrider „LLM as a Judge“-Ansätze bei der Bewertung von COBOL-Code. (Quelle: Fandina et al.: Beyond Blind Spots: Analytic Hints for Mitigating LLM-Based Evaluation Pitfalls, Abbildung 3, arXiv:2512.16272, 2025.)
Die Wirkung dieses Ansatzes ist in der Studie deutlich belegt und lässt sich gut anhand der oben zu sehenden Abbildung nachvollziehen. Während die nativen Modelle je nach Konfiguration zwischen rund 45 und 53 Prozent der Fehler erkannten, stieg die Erkennungsrate mit analytischen Hinweisen teils drastisch an. Besonders hervorgehoben wird das Modell gpt-oss-120b, das in der optimierten Hint-Konfiguration 94,4 Prozent der Fehler identifizierte und damit die beste Gesamtleistung erzielte. Auch andere Modelle wie DeepSeek-v3 profitierten spürbar von der hybriden Vorgehensweise, blieben jedoch teils darunter.
Gleichzeitig verweisen die Autoren auf eine wichtige Einschränkung: Durch die gezielte Fokussierung auf analytisch identifizierte Problemfelder würden andere Aspekte der Bewertung teilweise an Bedeutung verlieren. Nicht alle Fehler, die ein Modell zuvor ohne Hinweise erkannt habe, seien später erneut identifiziert worden. Die Hinweisinjektion erhöhe damit die diagnostische Präzision in bestimmten Bereichen, könne aber die Gesamtbreite der Bewertung einschränken, wenn sie nicht sorgfältig ausbalanciert werde.
Trotz dieser Einschränkungen sehen die Autoren ihre Arbeit als praxisnahen Beleg dafür, dass sich die Zuverlässigkeit KI-basierter Codebewertungen deutlich steigern lässt – ohne aufwendiges Retraining der Modelle. Für Unternehmen mit geschäftskritischen Legacy-Systemen ergibt sich daraus vor allem eine klare Botschaft: KI kann die Qualitätssicherung unterstützen, sollte aber gerade bei COBOL-Modernisierungen nicht isoliert eingesetzt werden. Hybride Ansätze aus analytischen Prüfungen und KI-Bewertung erscheinen aus Sicht der Studie als deutlich robusterer Weg. (td)





