Ob die Programmiersprache C bereits als Legacy-Technologie gilt, lässt sich nicht pauschal beantworten. Zwar stammt C aus den frühen 1970er-Jahren, zugleich ist sie bis heute ein zentraler Baustein moderner IT-Infrastrukturen. Betriebssysteme, Datenbanken, Embedded-Software und performanzkritische Komponenten setzen weiterhin auf C, nicht zuletzt wegen der hohen Kontrolle über Hardwareressourcen und der ausgereiften Toolchains.
Im Kontext von Legacy IT verschiebt sich die Bewertung jedoch. Entscheidend ist weniger das Alter der Sprache als die Art ihrer Nutzung. Dort, wo große, historisch gewachsene C-Codebasen mit geringer Änderungsfrequenz, begrenzter Dokumentation und knappen Fachressourcen betrieben werden, wird C zunehmend als Risiko wahrgenommen. Steigende Sicherheitsanforderungen, regulatorischer Druck und der Mangel an erfahrenen Entwicklern verstärken diesen Eindruck.
Vor diesem Hintergrund gewinnt Rust als speichersichere Alternative an Aufmerksamkeit. Die Diskussion um eine Migration von C nach Rust ist daher weniger eine Debatte über Programmiersprachen als über den Umgang mit technischer Schuld in kritischen Systemen. Ein aktuelles Forschungspaper im Journal Automated Software Engineering greift diese Fragestellung auf und untersucht, inwieweit sich C-Code mithilfe von Large Language Models automatisiert nach Rust übersetzen lässt.
Die Autoren stellen mit „RustFlow“ ein mehrstufiges Framework vor, das KI-gestützte Codeübersetzung mit technischen Prüfmechanismen kombiniert. C-Code wird zunächst mithilfe strukturierter Prompts und Zwischenrepräsentationen wie Abstract Syntax Trees oder LLVM IR in Rust überführt. Anschließend prüfen Compilerläufe und automatisiertes Fuzzing, ob Syntax und Laufzeitverhalten mit dem Original übereinstimmen. Erkannte Abweichungen werden iterativ durch weitere KI-Durchläufe korrigiert. In Experimenten erzielt dieser Ansatz höhere Erfolgsraten als frühere LLM-basierte Übersetzungsverfahren, heißt es in dem Paper.
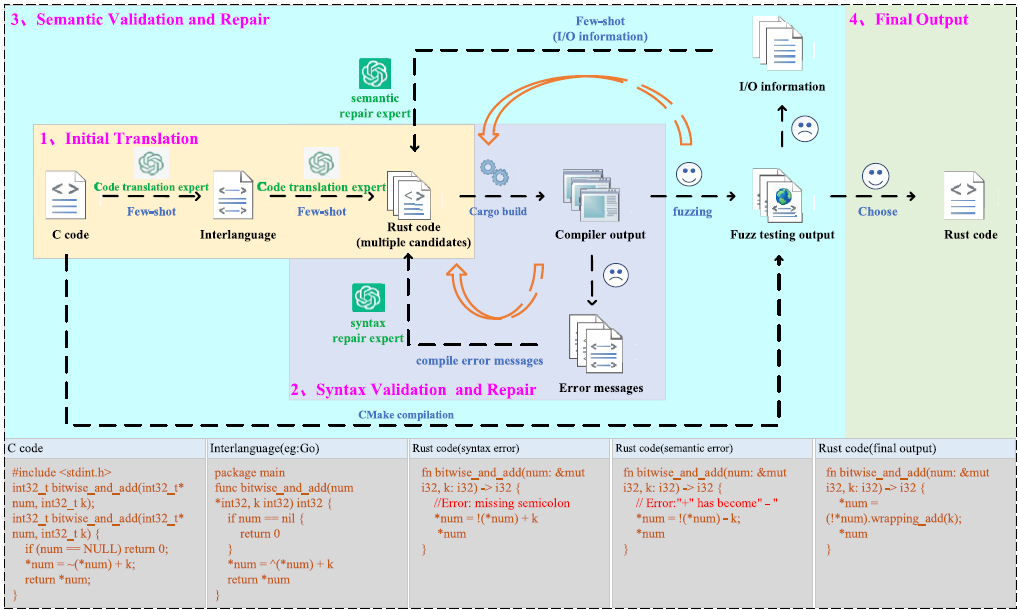
Das Framework „RustFlow“ kombiniert initiale Codeübersetzung mit Syntax- und Semantikvalidierung sowie iterativer Reparatur auf Basis von Compiler- und Fuzzing-Ergebnissen. (Quelle: Ruxin Zhang, Shanxin Zhang, Linbo Xie: A systematic exploration of C-to-Rust code translation based on large language models, Automated Software Engineering, Vol. 33, Article 21 (2026), Springer Nature.)
Für den produktiven Einsatz in klassischen Legacy-Umgebungen relativieren die Autoren ihre Ergebnisse jedoch selbst. Die Evaluation basiert überwiegend auf kleinen bis mittelgroßen Programmen und Funktionssammlungen, nicht auf historisch gewachsenen Gesamtsystemen. Zwar erreichen die Übersetzungen häufig eine erfolgreiche Kompilierung, die semantische Gleichwertigkeit – also identisches Laufzeitverhalten – bleibt insbesondere bei realitätsnäherem Code deutlich eingeschränkt. Zudem entfällt ein Großteil des Aufwands auf die nachgelagerte semantische Validierung, was die Skalierbarkeit des Ansatzes begrenzt.
Damit bestätigt die Studie vor allem eine bekannte Erkenntnis: KI kann punktuell bei der Analyse und Modernisierung unterstützen, ersetzt aber weder tiefes Systemverständnis noch Test- und Risikomanagement. Eine umfassende, automatisierte Migration von C-basierten Legacy-Systemen nach Rust bleibt auf absehbare Zeit ein Forschungsthema und ist vorerst kein realistisches Szenario für den laufenden Betrieb. (td)




