Forscher aus Brasilien beschäftigen sich mit einer Frage, die derzeit viele Unternehmen bei der Modernisierung ihrer Legacy-IT umtreibt: Wie können KI-Agenten zuverlässig an Altsystemen arbeiten, wenn wichtige Geschäftsregeln, Architekturentscheidungen und Sonderfälle nur im Quellcode oder im Wissen erfahrener Entwickler vorhanden sind?
Sanderson Oliveira de Macedo vom Federal Institute of Goiás und Ronaldo Martins da Costa von der Federal University of Goiás stellen dazu mit Reversa ein Framework vor, das Legacy-Software in nachvollziehbare operative Spezifikationen für KI-Agenten überführen soll. Ziel ist es, implizites Wissen aus bestehenden Anwendungen zu extrahieren und in einer Form aufzubereiten, die Wartung, Weiterentwicklung oder Migration unterstützt.
Der Ansatz basiert auf mehreren spezialisierten KI-Agenten. Diese analysieren die Ausgangssoftware, erfassen die Systemstruktur, identifizieren Geschäftsregeln, rekonstruieren die Architektur und erzeugen daraus Spezifikationen, Migrationsartefakte sowie Testgrundlagen. Ein besonderes Augenmerk legen die Autoren auf die Nachvollziehbarkeit der Ergebnisse. Jede Aussage soll auf konkrete Artefakte im Quellcode zurückgeführt werden können. Gleichzeitig werden Unsicherheiten ausdrücklich gekennzeichnet. Reversa unterscheidet zwischen bestätigten Erkenntnissen, abgeleiteten Annahmen und offenen Wissenslücken, die durch Menschen validiert werden müssen.
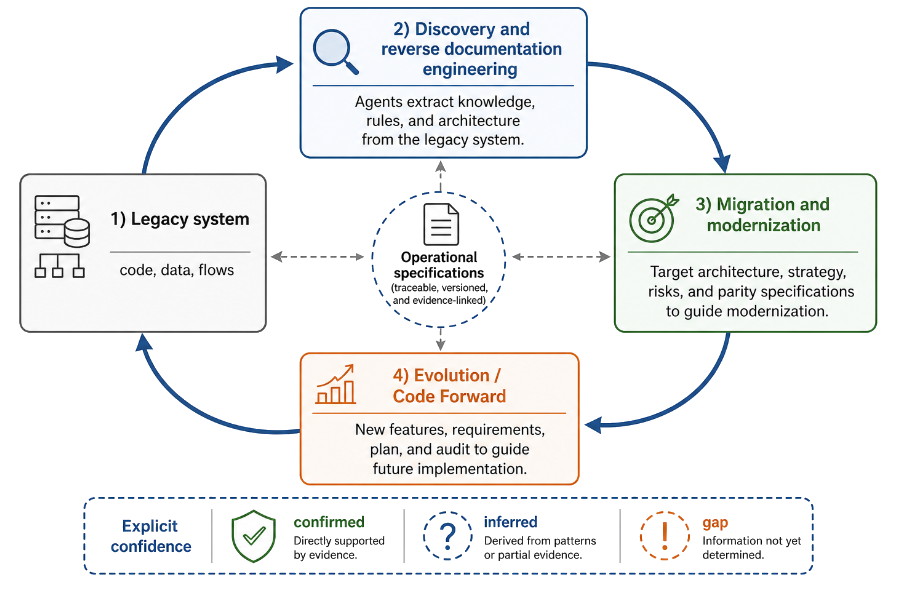
Das Reversa-Framework soll Wissen aus Legacy-Anwendungen extrahieren, in operative Spezifikationen überführen und als Grundlage für Modernisierung und Weiterentwicklung bereitstellen (Quelle: Macedo, Sanderson Oliveira de; Costa, Ronaldo Martins da: „Reversa: A Reverse Documentation Engineering Framework for Converting Legacy Software into Operational Specifications for AI Agents“, arXiv, Mai 2026, Figure 2. Darstellung unverändert übernommen)
Als Fallstudie dient die ATM-Anwendung „banco-atm“, eine in GnuCOBOL entwickelte Geldautomaten-Software. Die Legacy-Anwendung bildet typische Geldautomatenfunktionen wie Anmeldung, Kontostandsabfrage, Ein- und Auszahlungen, Überweisungen sowie Kontoauszüge ab. Die Datenhaltung erfolgt über .DAT-Dateien. Moderne Verfahren zur Testautomatisierung und Bereitstellung, etwa CI/CD-Pipelines oder containerisierte Umgebungen, kamen in der Ausgangsanwendung nicht zum Einsatz.
Die Pipeline erzeugte nach Angaben der Autoren 517 dokumentierte Erkenntnisse, 53 Gherkin-Szenarien für Paritätstests (vgl. Infobox unten) sowie einen Migrationsplan für eine Neuimplementierung in Go. Die finale Validierung der fachlichen Gleichwertigkeit und die Produktivsetzung wurden jedoch nicht abgeschlossen.
Lehrprojekt statt produktiver Bankanwendung
Genau dieser Punkt ist für die Einordnung der Ergebnisse wichtig. Die Autoren weisen selbst darauf hin, dass es sich um eine explorative Studie handelt. Die untersuchte ATM-Software stammt aus einem Lehrprojekt, besitzt keine produktive Nutzung und bildet lediglich einen stark vereinfachten Bankanwendungsfall ab. Aussagen über die Übertragbarkeit auf komplexe Kernbanksysteme, Mainframe-Landschaften oder regulatorisch geprägte Bankanwendungen lassen sich daraus bislang nicht ableiten.
Dennoch liefert die Veröffentlichung einen interessanten Impuls für die Diskussion um KI und Legacy-Modernisierung. Im Mittelpunkt steht nicht die automatische Übersetzung von COBOL-Code in moderne Programmiersprachen. Stattdessen argumentieren die Autoren, dass der eigentliche Mehrwert von KI zunächst in der strukturierten Extraktion von Wissen und der Erstellung belastbarer Spezifikationen liegen könnte.
Für Banken, Bausparkassen und Versicherungen ist insbesondere dieser Perspektivwechsel interessant. Während viele aktuelle Diskussionen rund um KI und Legacy-Transformation auf die eigentliche Code-Migration abzielen, versteht Reversa die systematische Erfassung von Geschäftsregeln, Abhängigkeiten und Anwendungswissen als vorgelagerten Schritt. Gerade in gewachsenen Anwendungslandschaften, in denen ein erheblicher Teil des Fachwissens nur implizit in Programmlogik, Datenstrukturen oder langjähriger Betriebserfahrung vorhanden ist, könnte ein solcher Ansatz helfen, die Grundlage für spätere Modernisierungsvorhaben zu schaffen. (td)
Was ist Gherkin?
Gherkin ist eine leicht verständliche Beschreibungssprache für Anforderungen und Testfälle. Der Name stammt aus dem Umfeld des Testframeworks Cucumber („Gurke“) und geht auf die englische Bezeichnung für eine Gewürzgurke zurück. In Modernisierungsprojekten wird Gherkin häufig genutzt, um das Verhalten bestehender Anwendungen zu dokumentieren und mit einer neuen Lösung zu vergleichen.





