In einer aktuellen Fachveröffentlichung stellen Samuel Ackerman, Wesam Ibraheem, Orna Raz und Marcel Zalmanovici von IBM Research die Robustheit gängiger KI-gestützter Modernisierungssysteme auf den Prüfstand.
In ihrem Paper „Evaluating perturbation robustness of generative systems that use COBOL code inputs“ untersuchen sie, wie empfindlich ein generatives Übersetzungssystem reagiert, wenn COBOL-Code vor der Verarbeitung minimal verändert wird. Hintergrund ist, so die Autoren, dass COBOL trotz seines Alters weiterhin zentrale Kernsysteme in Finanzinstituten und Versicherungen stütze – und damit eine kritische Rolle im Modernisierungskontext spiele.
Das Team beschreibt, dass bereits kleinste syntaktische Variationen – etwa veränderte Groß- und Kleinschreibung, zusätzliche Leerzeichen, alternative Zeilenumbrüche oder angepasste Kommentare – deutliche Auswirkungen auf die Ergebnisse eines KI-Systems haben können. So zeige beispielsweise die im Paper erläuterte Perturbation „tokens_uppercase“, bei der die Schreibweise nicht-literaler COBOL-Tokens vollständig in Großbuchstaben umgewandelt wird, wie anfällig die Systeme sein können: Obwohl COBOL semantisch unbeeindruckt bleibt, führen solche rein formalen Änderungen laut den Forschenden häufig zu eindeutig abweichenden KI-Übersetzungen ins Java-Format.
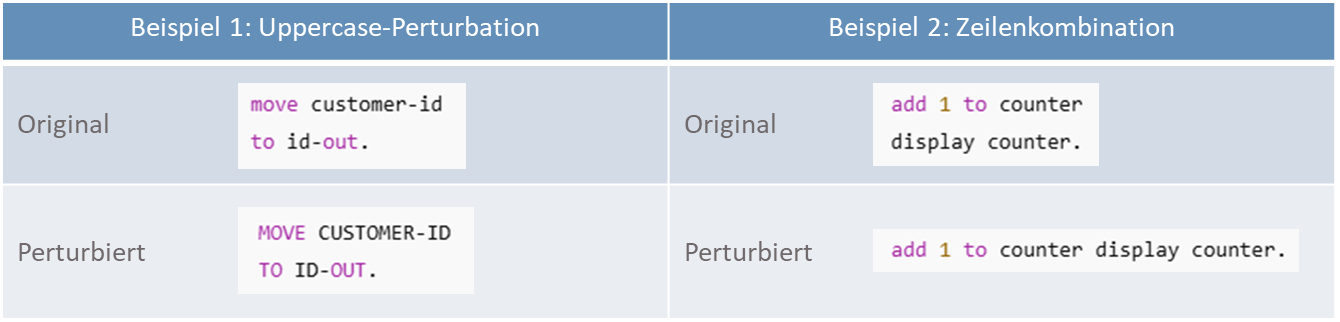
Zwei im Paper untersuchte Perturbationen: Schon einfache Formatvarianten wie Großschreibung oder das Zusammenziehen von Zeilen führten in den Tests zu abweichenden KI-Übersetzungen.
Für ihre Analyse erzeugten die vier Forscher aus realen COBOL-Abschnitten eine Vielzahl leicht veränderter Varianten, die sie durch ein generatives COBOL-zu-Java-Übersetzungssystem laufen ließen. Bewertet wurden anschließend nicht nur sichtbare Unterschiede im Output, sondern insbesondere messbare Qualitätsmetriken wie Parsbarkeit, Korrektheit von Variablenzugriffen, SQL-Übersetzung oder die Kompilierfähigkeit des resultierenden Java-Codes.
Die Auswertung zeigt nach Darstellung der Autoren, dass viele Systeme deutlich weniger stabil seien, als in Modernisierungsprojekten erwartet werde. In aggregierter Form habe sich gezeigt, dass rund ein Drittel der geringfügigen Codeabweichungen zu geänderten oder fehlerhaften Ergebnissen führten. Besonders anfällig seien KI-Modelle demnach bei Änderungen an Identifiernamen, Zeilenumbrüchen und Whitespace – also genau jenen stilistischen Details, die in gewachsenen Legacy-Umgebungen naturgemäß stark variieren.
Die Forscher folgern, dass Modernisierungsansätze, die KI-basierte Übersetzung oder Code-Generierung nutzen, zwingend robuste Vorverarbeitungsschritte, Standardisierung des Inputs und umfassende Tests benötigen. Ohne diese Maßnahmen bestehe das Risiko, dass scheinbar unbedeutende Unterschiede im COBOL-Code zu unerwarteten Ergebnissen führen – und damit potenziell ganze Modernisierungspipelines destabilisieren könnten. (td)





